提起Android的消息机制,相信大部分人不陌生。Android的消息机制主要指Handle的消息机制。Handler的使用过程很简单,通过它可以将一个任务切换到Handler所在的线程去执行。Handler的消息机制包括Handler、MessageQueue和Looper。
Handler的运行需要底层的MessageQueue和Looper的支撑。
- MessageQueue意思是消息队列,但其实它内部是用单链表结构来存储消息列表的,它内部存储了一组消息,向外提供插入和删除的工作。
- Looper则称为消息循环。毕竟MessageQueue只是用来存储消息的,而Looper就充当了处理消息的角色。它会以无限循环的形式去查看MessageQueue有没有新的消息,有的话就处理,否则就一直等待。
这里还要提出一个概念ThreadLocal,ThreadLocal虽然带了Thread,但是它并不是线程。它的作用就是可以在每个线程中互不干扰地存储\提供数据。我们知道Handler的构建需要用到当前线程的Looper。而ThreadLocal在这里的作用就是拿到线程的Looper提供给Handler,ThreadLocal可以轻松地获取每个线程的Looper。需要注意的线程默认是没有Looper的,也就是说我们需要自己构建一个Looper。当Handle需要Looper的时候,ThreadLocal就会拿到Handler所在线程的Looper给Handler。UI线程就是ActivityThread会在创建的时候就初始化Looper,所以在主线程可以不用自己创建Looper就使用Handler。
Android的消息机制概述
Handler创建时会采用当前线程的Looper构建消息循环系统,假如当前线程没有Looper呢,那么它当然会报错。
Handler创建完毕后,其内部的Looper和MessageQueue就可以和Handler一起协同工作了。 Handler可以通过post或者send投递信息,调用MessageQueue的enqueueMessage方法把这个消息塞到消息队列里面。Looper不断访问MessageQueue,发现有新消息到来了,就会处理这个消息。最后消息中的Runnable或者Handler的handlerMessage就会被调用。
注意Looper是运行在创建Handler所在的线程中的,这样一来Handler中的业务逻辑就被切换到创建Handler所在的线程中执行了。 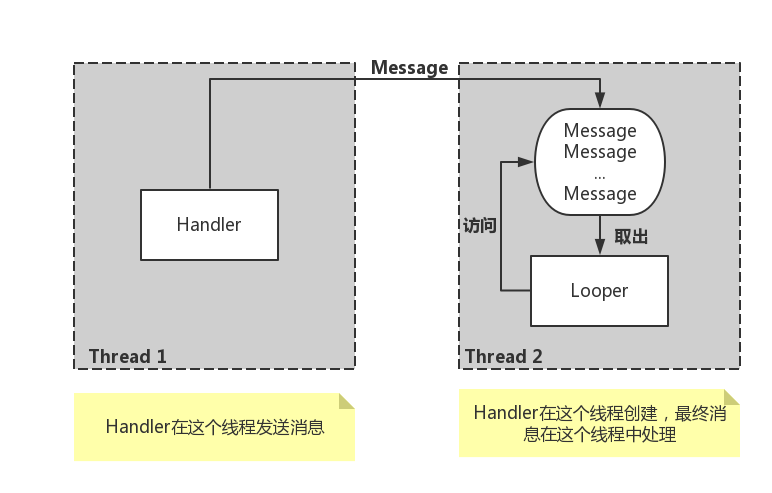
Android的消息机制分析
本节分为四个部分,分别是ThreadLocal、MessageQueue、Looper、Handler的工作原理
ThreadLocal的工作原理
ThreadLocal是一个线程内部的数据存储类,通过它可以在指定线程中存储数据,数据存储后,指定线程的数据只有在指定线程中可以获取到,其它线程则无法获取到。
一般来说,当某些数据是以线程为作用域并且不同线程有不同副本的时候,就可以考虑下ThreadLocal。我们的Looper显然就是这种情况,不同线程中都有一个Looper,但这些Looper又彼此不同。
还有另一种情况是在一个线程环境下,复杂逻辑下的对象传递。如果一个线程任务中函数调用栈比较深,而我们要把一个监听器传递下去,让底层的方法也能调用监听器,常规方法有两个:
- 将监听器作为函数的参数一级一级往下传递
- 将监听器作为静态变量供线程访问
这两种方法都是有局限性的,第一种当函数调用栈很深的时候,这种做法是不可接受的,会让程序的设计很糟糕。
第二种方法是可以接受的,但这种方法又不具有可扩充性。当我有10个线程并发执行,那么还要写10个监听器吗。
而ThreadLocal可以让监听器作为线程内的全局变量而存在,在线程内部可以通过get来获取监听器,当有多个线程的时候,由于ThreadLocal的特性,每个线程有不同的监听器副本,就不用在线程内声明监听器了。
说了这么多,我们可以用代码实践一下。
定义一个ThreadLocal
private ThreadLocal<Boolean> mBooleanThreadLocal = new ThreadLocal<Boolean>();
然后分别在主线程、子线程1和子线程2设置并访问它的值
//主线程
mBooleanThreadLocal.set(true);
Log.d(TAG, mBooleanThreadLocal.get());
//子线程1
new Thread("Thread#1"){
@Override
public void run(){
mBooleanThreadLocal.set(false);
Log.d(TAG, mBooleanThreadLocal.get());
}
}
//子线程2
new Thread("Thread#2"){
@Override
public void run(){
Log.d(TAG, mBooleanThreadLocal.get());
}
}
- 主线程 log日志的值为true
- 子线程1 log日志的值为false
- 子线程2 log日志的值为null
ThreadLocal之所以这么特别,是因为不同线程访问同一个ThreadLocal的get方法,ThreadLocal会在各自的线程里取出一个数组,然后根据索引找出对应的value,显然,不同线程的数据是不同的。
首先看ThreadLocal的set方法
public void set(T value){
Thread currentThread = Thread.currentThread();//获取当前线程
Values values = values(currentThread);//获取当前线程的localvalus
if(values == null){
values = initializeValues(currentThread);
//如果localValues为null,则初始化
}
values.put(this, value);
//线程的localValues存储线程的ThreadLocal和其对应的值。
}
下面看下ThreadLocal的值是如何在localValues中进行存储的。localValues中有一个数组private Object[] table,ThreadLocal的值就存在于这个数组中。 下面看下localValues的put方法
void put(ThreadLocal<?> key, Object value) {
cleanUp();
// Keep track of first tombstone. That's where we want to go back
// and add an entry if necessary.
int firstTombstone = -1;
// ThreadLocal的hash值是key
for (int index = key.hash & mask;; index = next(index)) {
// 通过hash值索引获取TheadLocal的reference
Object k = table[index];
// 如reference已经存在于table中,更新TheadLocal的value,value的索引总比TheadLocal的reference大一位
if (k == key.reference) {
// Replace existing entry.
table[index + 1] = value;
return;
}
//如果TheadLocal的reference不存在于table中,用TheadLocal的hash值作为索引,把TheadLocal的reference存进去,用TheadLocal的hash值加一存储TheadLocal的value
if (k == null) {
if (firstTombstone == -1) {
// Fill in null slot.
table[index] = key.reference;
table[index + 1] = value;
size++;
return;
}
// Go back and replace first tombstone.
table[firstTombstone] = key.reference;
table[firstTombstone + 1] = value;
tombstones--;
size++;
return;
}
// Remember first tombstone.
if (firstTombstone == -1 && k == TOMBSTONE) {
firstTombstone = index;
}
}
}
这里分析ThreadLocal的get方法
public T get(){
//Optimized for the fast path
//获取当前线程
Thread currentThread = Thread.currentThread();
//获取当前线程的localvalus
Values values = values(currentThread);
if(values != null){
Object[] table = values.table;
int index = hash & values.mask;
//如果当前的ThreadLocal的hash值在table中有记录的话,说明localvalus已经存储了当前线程的ThreadLocal的reference
if(this.reference == table[index]){
//在table中,返回当前的ThreadLocal的hash值加一的对象,就是ThreadLocal的value
return (T) table[index + 1];
}
} else {
//如果localValues为null,则初始化
values = initializeValues(currentThread);
}
return (T) values.getAfterMiss(this);
}
从ThreadLocal的set和get方法中可以看出,他们所操作的对象都是当前线程的localValues对象的table数组。因此对不同线程访问ThreadLocal,它们对ThreadLocal的操作都仅限于当前线程的内部,这就是ThreadLocal可以在不同线程互不干扰存储修改数据的奥秘。 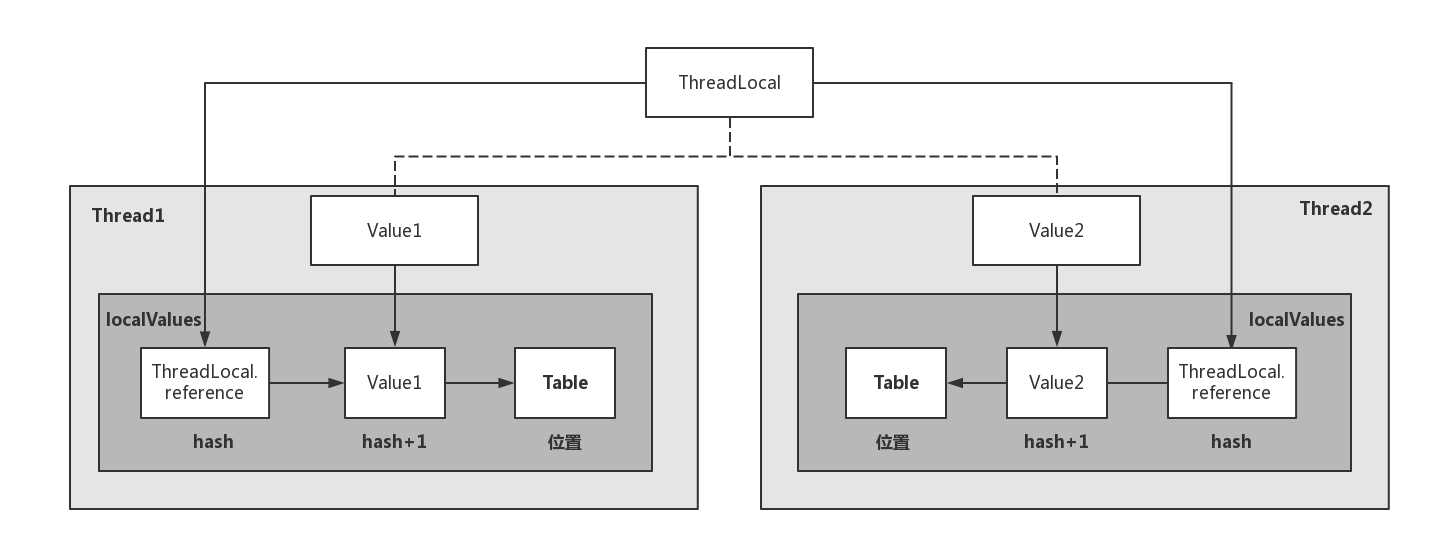
MessageQueue的工作原理
MessageQueue是以单链表为数据结构来维护消息列表的,单链表在插入和删除上比较有优势。
先看下MessageQueue的enqueueMessage和next方法的实现
boolean enqueueMessage(Message msg, long when)
//mMessages是头部
Message p = mMessages;
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
} else {
Message prev;
for (;;) {
prev = p;
p = p.next;
/*也就是说找到一个时间比msg时间大的message(即p)
就跳出循环,说明msg应该插在p的前面,插在prev的后面
,如果找不到也要跳出循环,说明msg比链表中所有的项的
时间都要大,排在最后面,也就是在prev的后面,p的前面
,此时p为null*/
if (p == null || when < p.when) {
break;
}
}
msg.next = p;
prev.next = msg;
}
if (needWake) {
nativeWake(mPtr);
}
}
先看下新消息需要放到队头的情况:p == null || when == 0 || when < p.when。即队列为空,或者新消息需要立即处理,或者新消息处理的事件比队头消息更早被处理。这时只要让新消息的next指向当前队头,让mMessages指向新消息即可完成插入操作。 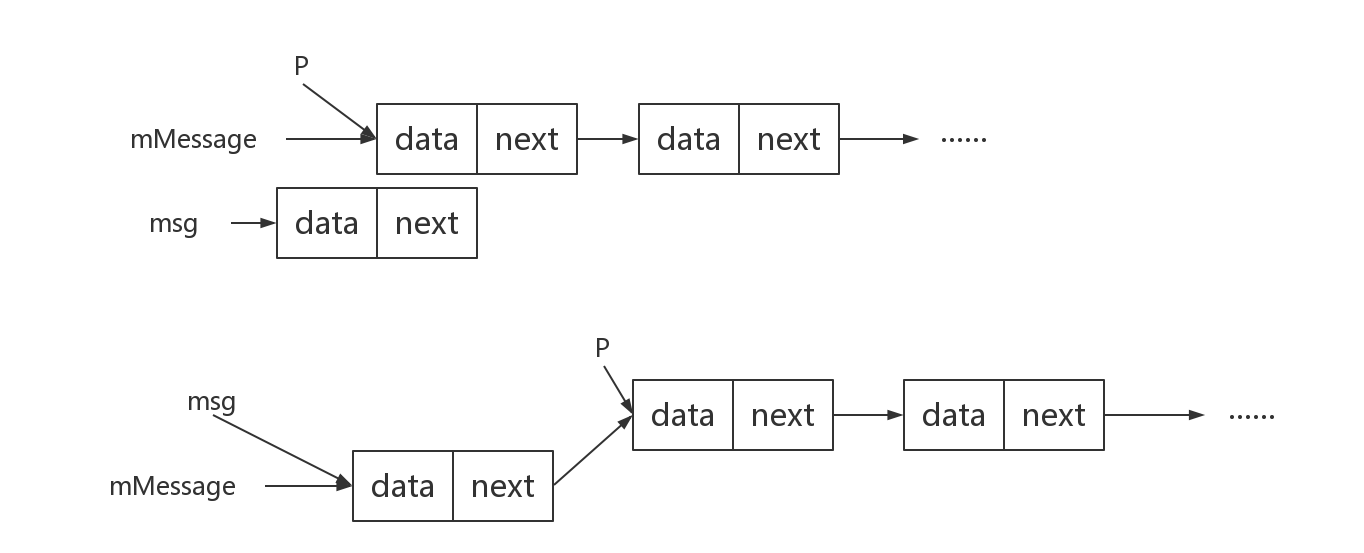
除了上述三种情况就需要遍历队列来确定新消息位置了,下面结合示意图来说明。 假设当前消息队列如下 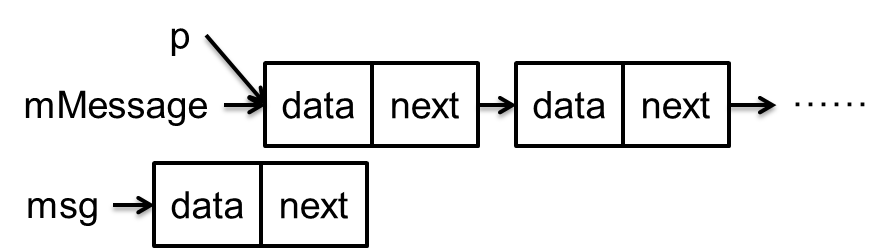
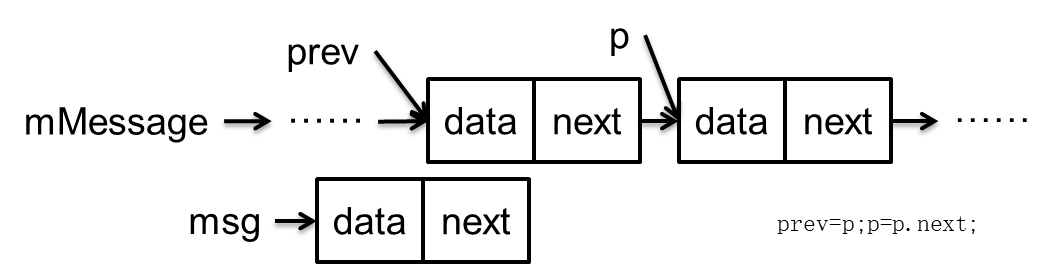
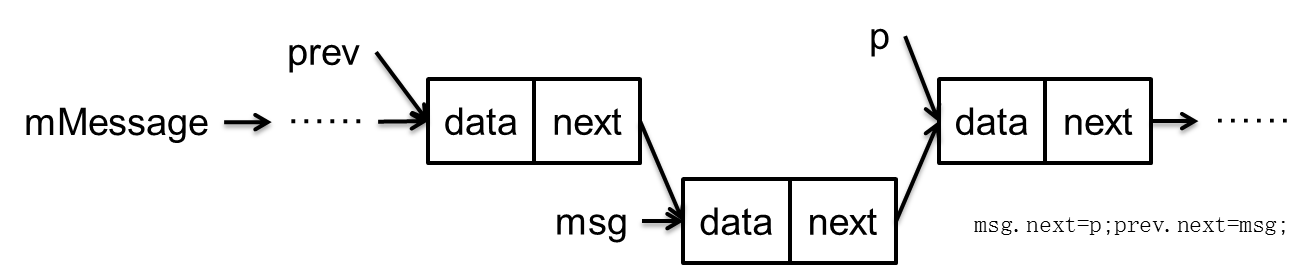
接下来我们看下next方法的实现
Message next() {
int nextPollTimeoutMillis = 0;
for (;;) {
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
nextPollTimeoutMillis = -1;
}
}
nextPollTimeoutMillis = 0;
}
}
可以发现next是一个无限循环的方法,如果消息队列中没有消息,那么next方法会一直阻塞在这里。当有新消息到来的时候,next方法会返回这条信息并从单链表中移除 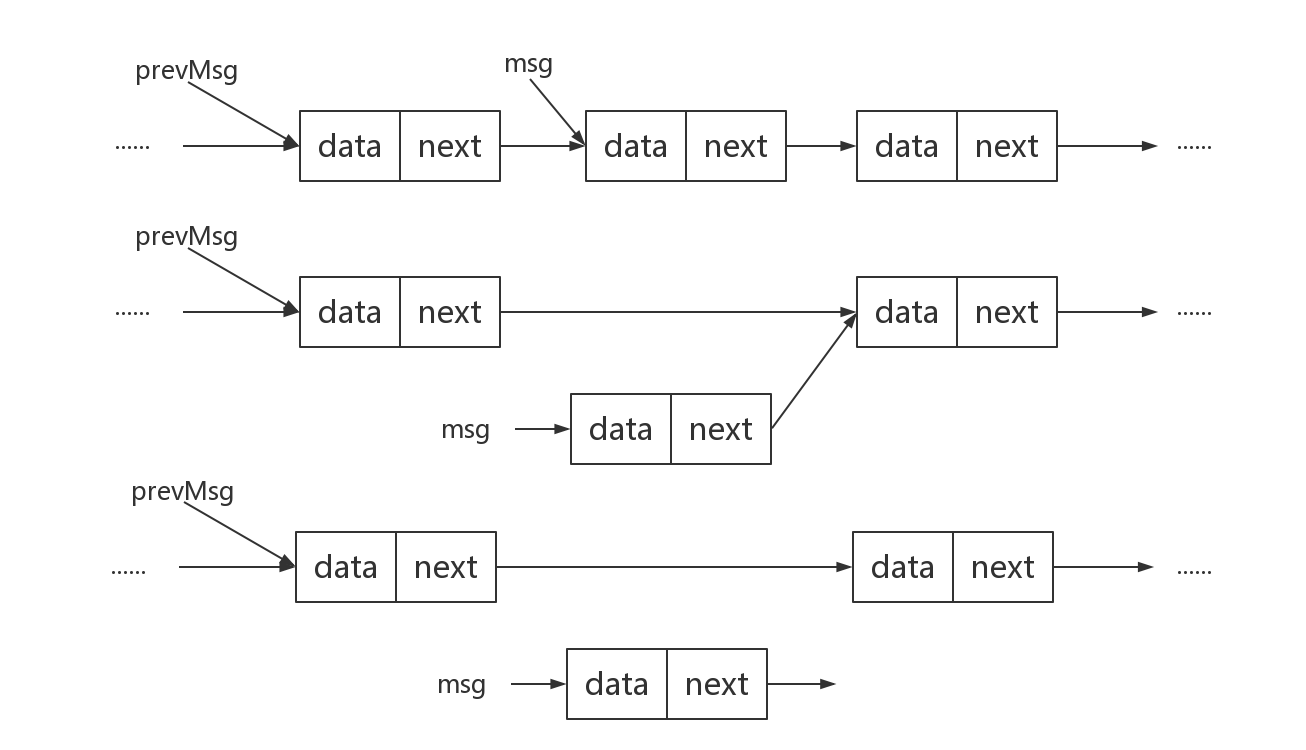
Looper的工作原理
Looper会不断地从MessageQueue中查看是否有新消息,有新消息就立刻处理,否则就一直阻塞在那里。在构造方法里它会创建一个MessageQueue,然后将当前线程的对象保存起来。
private Looper(boolean quitAllowed){
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread().
}
现在问题是如何给一个线程创建Looper呢?我们通过Looper.prepare()就可以给当前线程创建一个Looper,接着通过Looper.loop()来开启消息循环。
new Thread("Thread#2"){
@Override
public void run(){
Looper.prepare();
Handler handler = new Handler();
Looper.loop()
}
}.start();
其实,Looper也是可以退出的,Looper提供了quit和quitSately来退出一个Looper。二者的区别是
- quit会直接退出Looper
- quitSately只是设定一个标记,等待MessageQueue所有信息处理完了才安全退出。
Looper退出后,Handler发送的消息会失败,send方法返回false。
所以在子线程中,如果手动创建了Looper,在所有事情都完成后应当终止消息循环,退出Looper,否则子线程都会处于等待状态。 Looper最重要的就是loop方法,它的代码如下
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
// Make sure that during the course of dispatching the
// identity of the thread wasn't corrupted.
final long newIdent = Binder.clearCallingIdentity();
if (ident != newIdent) {
Log.wtf(TAG, "Thread identity changed from 0x"
+ Long.toHexString(ident) + " to 0x"
+ Long.toHexString(newIdent) + " while dispatching to "
+ msg.target.getClass().getName() + " "
+ msg.callback + " what=" + msg.what);
}
msg.recycleUnchecked();
}
}
这个方法也比较好理解,loop方法是一个死循环,唯一跳出循环的方法是MessageQueue的 next方法返回了null。当Looper的quit方法被调用的时候,Looper会调用MessageQueue的quit或quitSately方法来通知消息队列退出,当MessageQueue被标记为退出状态时,它的next方法就会返回null。
当没有消息时,MessageQueue的 next方法也不会返回null,而是会一直阻塞在那里,也就是说Looper必须退出,否则loop会不断循环下去。
如果MessageQueue的next返回了新消息,Looper就会处理这个消息: msg.target.dispatchMessage(msg); 这里的msg.target是发送这个消息的Handler对象,这样Handler对象发送的消息就交给它的dispatchMessage方法去处理了。由于dispatchMessage是在Looper中执行的,而Looper又是位于创建Handler的线程内的,这样就把消息切换到Handler创建时所在的线程中处理了。
Handle的工作原理
Handler的工作主要包括消息的发送和接收。消息的发送可以通过post的一系列方法和send的一系列方法实现。而post的一系列方法最终又是通过send的一系列方法实现的。
public final boolean sendMessage(Message msg){
return sendMessageDelayed(msg, 0);
}
public final boolean sendMessageDelayed(Message msg, long delayMillis){
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
可以看到,Handle发送消息的过程仅仅是向MessageQueue中插入了一条消息。MessageQueue的next就会返回这个消息给Looper,Looper就会把信息交给Handler处理,即调用Handler的dispatchMessage方法。
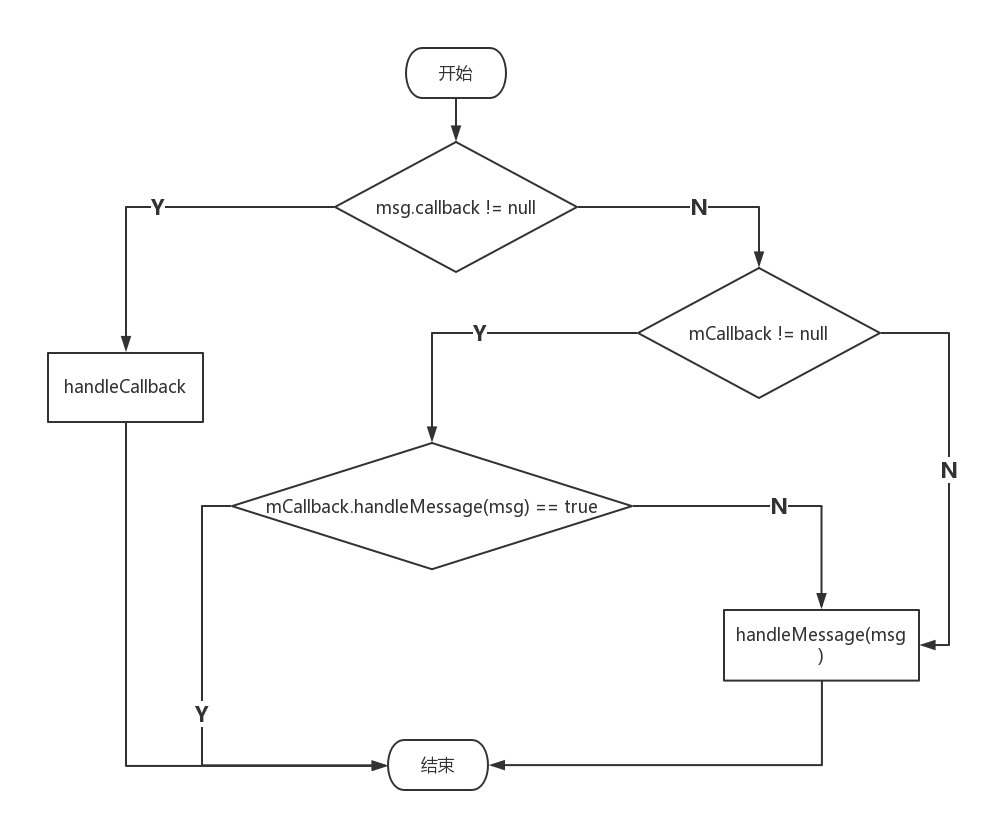
public void dispatchMessage(Message msg){
if(msg.callback != null){
handleCallback(msg);
}else {
if (mCallback != null){
if(mCallback.handleMessage(msg)){
return;
}
}
handleMessage(msg);
}
}
Handler处理消息的过程如下:
- 首先检查Message的callback是否为null,不为null的话就通过handleCallback来处理消息,Message的callback实际上就是一个Runnable对象,即Handler的post所传递的Runnable。handleCallback的逻辑也很简单:
private static void handleCallback(Message message){ message.callback.run(); }逻辑就是直接让Runnable执行起来。
- 其次如果callback为null的话,那么检查mCallback是否为null,不为null就调用mCallback的handleMessage方法来处理消息。mCallback是一个接口,它的定义如下:
public interface Callback{ public boolean handleMessage(Message msg); }这种方法成立的前提是,你在创建Handler的时候,就把Callback传进去了。如:Handler handler = new Handler(callback);在日常开发中,我们常常是派生Handler的子类重写它的handleMessage来处理具体消息,而是用Callback就可以不用派生Handler的子类来创建Handler,处理逻辑都写在Callback里面了。
- 最后,如果mCallback是null,也就是说我们没有用Handler handler = new Handler(callback)来创建一个Handler,而是派生Handler的子类重写它的handleMessage来创建一个Handler。这就会直接调用handleMessage(msg);来处理消息。